How To Create A Data Filing System
Part II. Planning The Output
Jim Fowler
Part I of this article covered the goals to keep in mind and the kinds of disk files that could be used in a data filing system. From painful experience, I can tell you that the most important planning begins with the output functions of a program. This will determine the best way to file the data. That will, in turn, define the nature of the input functions. There are two aspects to the problem: how to encode the data and how to search the file. Again, it's best to work backwards. Let's look at searching first.
Searching Takes Time
Let's say you want to search your file. You have data that you want to match up with data in the file – maybe an author's name – and you want the titles of the books by that author. The author's name will be used as the key, and you want to retrieve all the records having an author's name identical to the key.
First, you have arranged the data within the records so the program can find the author's name. Maybe it is the first 16 bytes in the record. You can read that from the disk and compare it to the key. If they match, you have a hit, otherwise you have a miss. Maybe you want all the hits to be printed or displayed on the screen. Maybe you want both, or, as I arranged to do in one of my programs, you can preview a hit on the screen and opt to have it printed for later use.
However, there is a serious problem here. It may take only a second or two to get the author's name from the disk, and the comparison with the key runs quite fast. But if you have a thousand records to search through at one second each, it's going to take about 20 minutes to go through the file – and that's not allowing any time for the printer to print or the user to preview records on the screen. You could flip through a lot of cards in a card file in 20 minutes. How can you get around this?
Creating An Index File
The answer is an index file; see Figure 1. You keep a separate file of authors' names, probably in the same order as the records on the disk. Because this file sits in RAM, searching is much faster. Furthermore, you may be able to make the program search while contemplating the last hit on the screen, or while the printer is printing. Then, the only delay is in retrieving the first hit. After that, the search appears instantaneous. Index files are almost a necessity if you have many records and want to retrieve them in anything other than top-to-bottom order. Even a mailing list ought to be retrievable in alphabetical order or by zip code, for example.
This brings up another problem: the index file.(or files) will have to be recorded on the disk, too. The longer the file, the longer it will take to save it when you are through entering data – and the more space you will need in RAM. So give thought to keeping index files as short as you can and as easy to save as possible. This means using index words (entries into the index file) which are both short and packed with information. Look at your data with this in mind.
I found that last names can usually be reduced to the first eight letters. The number of false hits is quite tolerable, especially if you plan to preview the hits for other reasons. Now and then you will look for WADSWORTH and get WADSWORTHENSON, but that has to be traded off against using a nine-letter index word which makes a thousand-record index a thousand bytes longer. You will have to compromise somewhere.
Two Kinds Of Search
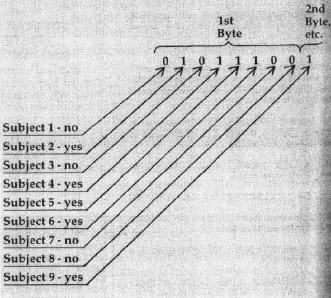
Another consideration is that there are two fundamentally different kinds of search. One is a match: like the author's name, it's an identity match. The other is a topic match. An example of this is looking for books on certain subjects. In this second case, the subjects are "contained in" the record, but the book might also include subjects you haven't asked for and don't care about. The match isn't an identity; let's call it a "contained-in" match. How you implement this depends on how you encode the information on subjects.
I recommend that you use a bitmap type of code as illustrated in Figure 2. Program 1 gives a sample "identity search" in both BASIC and machine language. Program 2 does the same for the "contained-in" search.
There are a few techniques you need to use. First, you set up a general buffer to use in inputting keys and index words. The same routine used for generating an index word (say, from an author's last name) can be used to put the comparable index word into this buffer. Carefully consider how you encode the data in light of your retrieval problems. A few hours at this stage can make a tremendous difference in the result.
If your key for an identity search is not as long as the index words compared with it, fill the rest of the space with nulls. In the search routine (as shown in the programs) the program returns as soon as it hits a null. That way you can input "SMITH" and find all the Smiths or even just "S" and get all the authors whose names start with S.
If you want to retrieve records by a combination of these search methods, you can do it by using them in sequence. For example, do an identity search first. Then, when you have a hit, check for the second kind, the contained-in search. If the record passes both tests, you have a full hit. This allows you to set up keys that are a mixture of "must-have" and "don't-care" data.
Record Formatting
Now it is time to decide how your records are to be set up. If you are using relative records (each record the same length — like pigeonholes), you have the same arrangement problem within a record as you had deciding the type of record to use.
Your record can be divided up into "fields." Each record will have the same size fields. One field will be the author's name, another the year of publication (four bytes can encode a four-digit year, or you can subtract 1792 from the year and encode all the years from 1792 to 2047 with only one byte). Each field will have to be big enough to hold the largest string of data you will ever want to store there. Book titles in my file take 80 bytes, and even then I have to condense the longer titles.
Take your time deciding your record format. Since you will be reading a record from the disk only to display it (not for searching purposes), it is best to have the data in a few long strings rather than in shorter chunks. Author and year could be one ASCII string – then the input from the disk and the display on the screen (or printer) is easy to program. Numeric data can be either floating point or integer.
Working with output is the next step, and we'll cover that in the next issue.
Figure 1: Index files contain parts of records for rapid searching.
Program 1: Identity Search In BASIC And Machine Language
Start with SYS (or JSR) to "BEGIN"; routine will return with number of record hit in register. If that number is zero, then no more hits. After a hit, continue search with SYS (orJSR) to "DECPT."
| "BEGIN" | Put KEY into BUFFER. Set POINTER from NEXT EMPTY RECORD No. |
| "DECPT" | Decrement POINTER by one. If zero, then RETURN. |
(in BASIC)
10 AD=POINTER*LEN+OFFSET 20 FOR I = 0 TO LEN-1 30 X = PEEK(BUFFER+I) 40 IF X=0 THENRETURN 50 IF PEEK (AD+I) <> GOTO "DECPT" 60 NEXT I: RETURN
(in machine language)
Put POINTER*LEN in REGISTER Add OFFSET to REGISTER
LDY #0
"CONT"LDA (REGISTER),Y
BEQ "END"
CMP (BUFFER),Y
BNE "DECPT"
INY
CPY #LEN
BCC "CONT"
"END" RTS
Note: LEN = index word length
OFFSET = address of zero'th index word
Program 2: Contained-in Search In BASIC And Machine Language
The operation is similar to routine in Program 1.
| "BEGIN" | Put KEY into BUFFER. Set POINTER from NEXT EMPTY RECORD No. |
| "DECPT" | Decrement POINTER by one. If zero, then RETURN. |
(in BASIC)
10 AD=POINTER*LEN+OFFSET 20 FOR I=0 TO LEN-1 30 X=PEEK(BUFFER+I) 40 IF(PEEK(AD+I)ANDX)<>X THEN RETURN 50 NEXT I : RETURN
(in machine language)
Put POINTER*LEN in REGISTER Add OFFSET to REGISTER
LDY #0
"CONT"LDA(POINTER),Y
EOR #$FF
EOR (BUFFER), Y
INY
CPY #LEN
BCC "CONT"
RTS
Note: LEN is index word length OFFSET is address of zero'th index word.